
上周回顾
- pc端
- YUV420的排列
- 用SDL渲染YUV和RGB,并封装成库
- 帧率控制
- AVFrame用来存图像帧的
- rk3566端
- 无
本周计划
- 技能储备
- ffmpeg图像处理--c4
- 264、265编解码--c5c6
- 封装ffmpeg--c7
- rtsp解封装--c8
- pc端
- 搭建一个基本qt应用框架
- rk3566端
- 尝试编译一个支持拓展板上网口的uboot
- 尝试交叉编译一个qt或者sdl
本周记录
#daily/25/10/13
FFmpeg-SWS接口
SWS接口
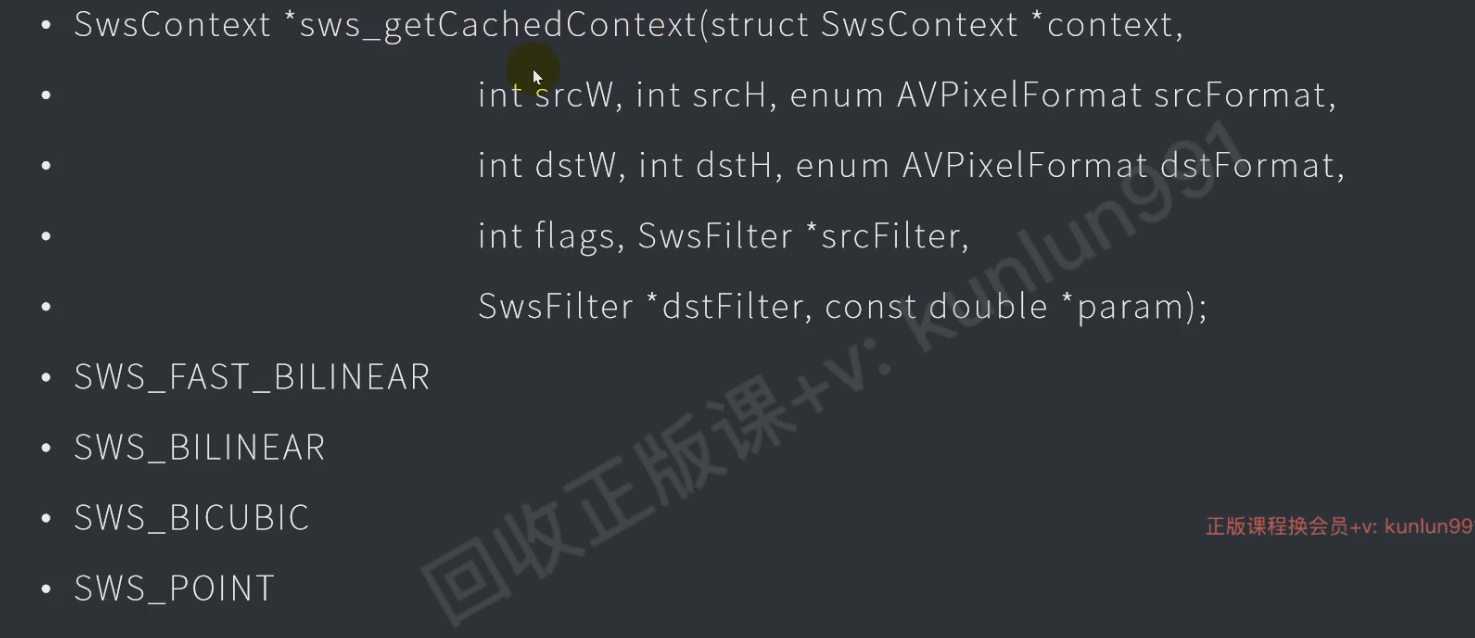
//创建上下文
sws_sws_getCachedContext();
//转换格式
sws_scale();YUV转换成RGB
#daily/25/10/14
具体查看 011_test_sws_scale
效果
这里主要用的函数就是 sws_scale 来转换格式,会写入到此一个数组,然后把这个数组的内容写道文件就好了。
#include <iostream>
#include <fstream>
extern "C"
{
#include <libswscale/swscale.h>
#include <libavcodec/avcodec.h>
}
#pragma comment(lib,"avcodec.lib")
#pragma comment(lib,"swscale.lib")
#define YUV_PATH "C:\\Users\\Shelton\\Workspaces\\code\\vs\\study_ffmpeg\\assets\\640_360_30.yuv"
#define ARGB_PATH "C:\\Users\\Shelton\\Workspaces\\code\\vs\\study_ffmpeg\\assets\\1280_720_30.argb"
using namespace std;
void yuv_to_rgb();
int main()
{
yuv_to_rgb();
}
void yuv_to_rgb()
{
int width_yuv = 640;
int height_yuv = 360;
int width_rgb = 1280;
int height_rgb = 720;
ifstream ifs;
ofstream ofs;
ifs.open(YUV_PATH, ios::binary);
ofs.open(ARGB_PATH, ios::binary);
// frame_buf
auto buf_y = make_unique<unsigned char[]>(width_yuv * height_yuv);
auto buf_u = make_unique<unsigned char[]>(width_yuv * height_yuv / 4);
auto buf_v = make_unique<unsigned char[]>(width_yuv * height_yuv / 4);
auto buf_rgb = make_unique<unsigned char[]>(width_rgb * height_rgb * 4);
unsigned char* rgb[] = { buf_rgb.get() };
unsigned char* yuv[] = { buf_y.get(), buf_u.get(), buf_v.get() };
int rgb_line_szes[1] = { width_rgb * 4 };
int yuv_line_sizes[3] = { width_yuv, width_yuv / 2, width_yuv / 2 };
struct SwsContext* yuv2rgb = nullptr;
// yuv转rgb
for (;;)
{
// 读取yuv平面数据
ifs.read((char*)buf_y.get(), width_yuv * height_yuv);
ifs.read((char*)buf_u.get(), width_yuv * height_yuv / 4);
ifs.read((char*)buf_v.get(), width_yuv * height_yuv / 4);
// 检查是否成功读取了所有数据
if (ifs.gcount() == 0) break; // 没有读取到任何数据,退出
// 获取上下文,NULL时会创建上下文
yuv2rgb = sws_getCachedContext(
yuv2rgb, // 上下文
width_yuv, height_yuv, AV_PIX_FMT_YUV420P, // 输入数据 宽高格式
width_rgb, height_rgb, AV_PIX_FMT_ARGB, // 输出数据 宽高格式
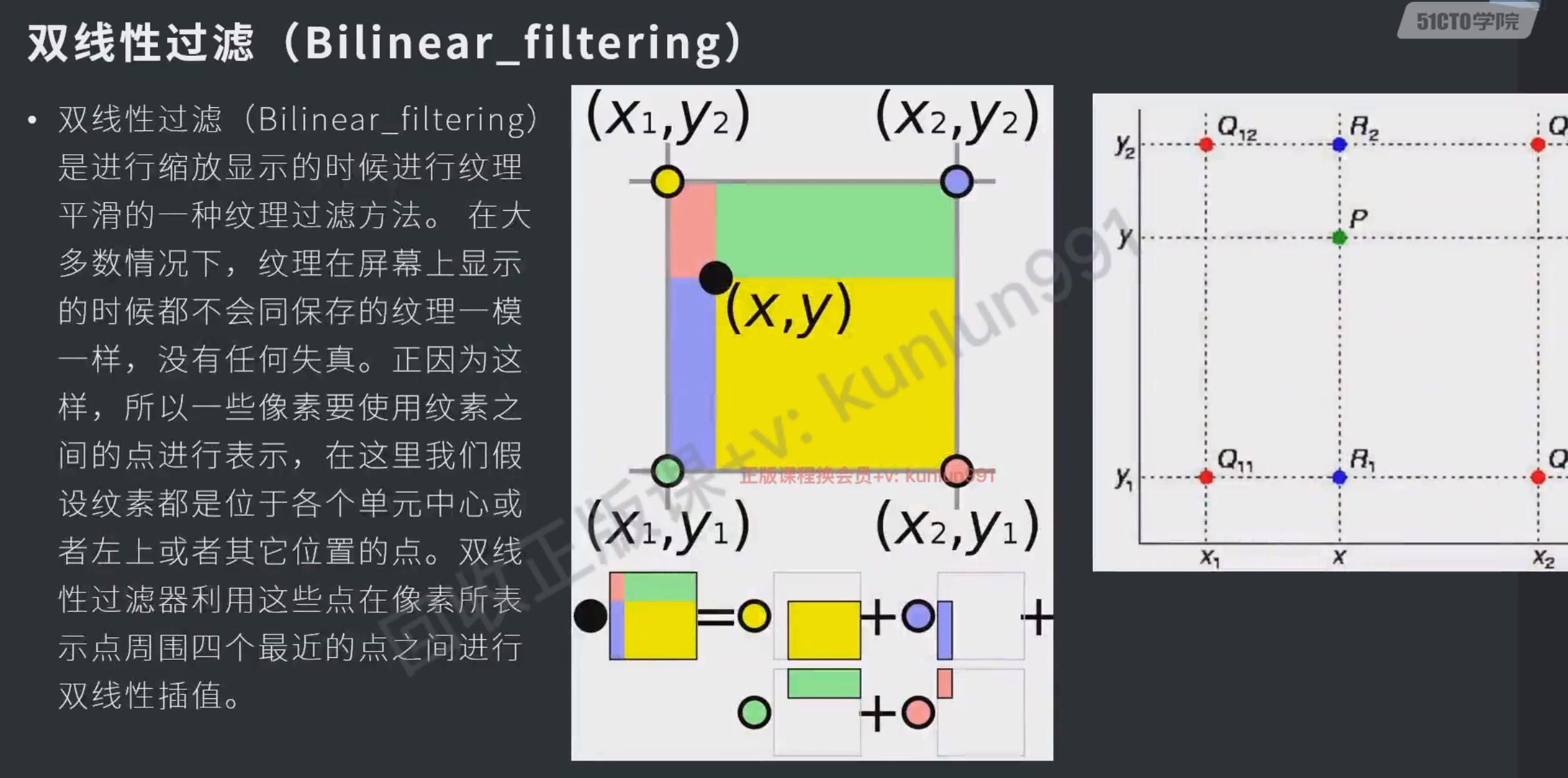
SWS_BILINEAR, // 抗锯齿算法
NULL, NULL, NULL // 过滤器参数
);
// 转换
sws_scale(
yuv2rgb, // 上下文
yuv, // 输入图像数组
yuv_line_sizes, // 输入图像行字节数数组
0, // Y轴图像
height_yuv,
rgb, // 输出图像数组
rgb_line_szes // 输出图像行字节数
);
// 写文件
ofs.write((char*)buf_rgb.get(), width_rgb * height_rgb * 4);
static int cnt = 0;
cnt++;
cout << "write" << cnt << endl;
}
ifs.close();
ofs.close();
}测试rgba文件是否正确转换
把 rgba 用 ffmpeg命令行重新转换成mp4去播放
ffmpeg -f rawvideo -pixel_format argb -video_size 1280x720 -framerate 30 -i ./1280_720_30.argb ./1280_720_30.mp4YUV转换成RGB
具体查看 011_test_sws_scale
效果
void rgb_to_yuv()
{
// 新建AVFrame对象
AVFrame* frame_rgb = av_frame_alloc();
AVFrame* frame_yuv = av_frame_alloc();
// 填写参数
frame_rgb->width = 1280;
frame_rgb->height = 720;
frame_rgb->format = AV_PIX_FMT_ARGB;
frame_rgb->linesize[0] = frame_rgb->width * 4;
frame_yuv->width = 320;
frame_yuv->height = 180;
frame_yuv->format = AV_PIX_FMT_YUV420P;
frame_yuv->linesize[0] = frame_yuv->width; // y
frame_yuv->linesize[1] = frame_yuv->width / 2; // u
frame_yuv->linesize[2] = frame_yuv->width / 2; // v
// 分配缓冲区
av_frame_get_buffer(frame_rgb, 0);
av_frame_get_buffer(frame_yuv, 0);
// 打开文件
ifstream ifs;
ofstream ofs;
ifs.open(ARGB_PATH,ios::binary);
ofs.open(YUV2_PATH,ios::binary);
// 新建上下文
SwsContext* context = nullptr;
for (;;)
{
// 读文件
ifs.read((char*)frame_rgb->data[0], frame_rgb->width * frame_rgb->height * 4);
if (ifs.gcount() == 0) break;
context = sws_getCachedContext(
context,
frame_rgb->width, frame_rgb->height, (AVPixelFormat)frame_rgb->format,
frame_yuv->width, frame_yuv->height, (AVPixelFormat)frame_yuv->format,
SWS_BILINEAR,
0, 0, 0
);
sws_scale(
context,
frame_rgb->data,
frame_rgb->linesize,
0,
frame_rgb->height,
frame_yuv->data,
frame_yuv->linesize
);
// 写文件
ofs.write((char*)frame_yuv->data[0], frame_yuv->width * frame_yuv->height);
ofs.write((char*)frame_yuv->data[1], frame_yuv->width * frame_yuv->height / 4);
ofs.write((char*)frame_yuv->data[2], frame_yuv->width * frame_yuv->height / 4);
static int cnt = 0;
cout << "write" << cnt++ << endl;
}
// 关文件
ifs.close();
ofs.close();
av_frame_free(&frame_yuv); // 会自动释放缓冲区
av_frame_free(&frame_rgb);
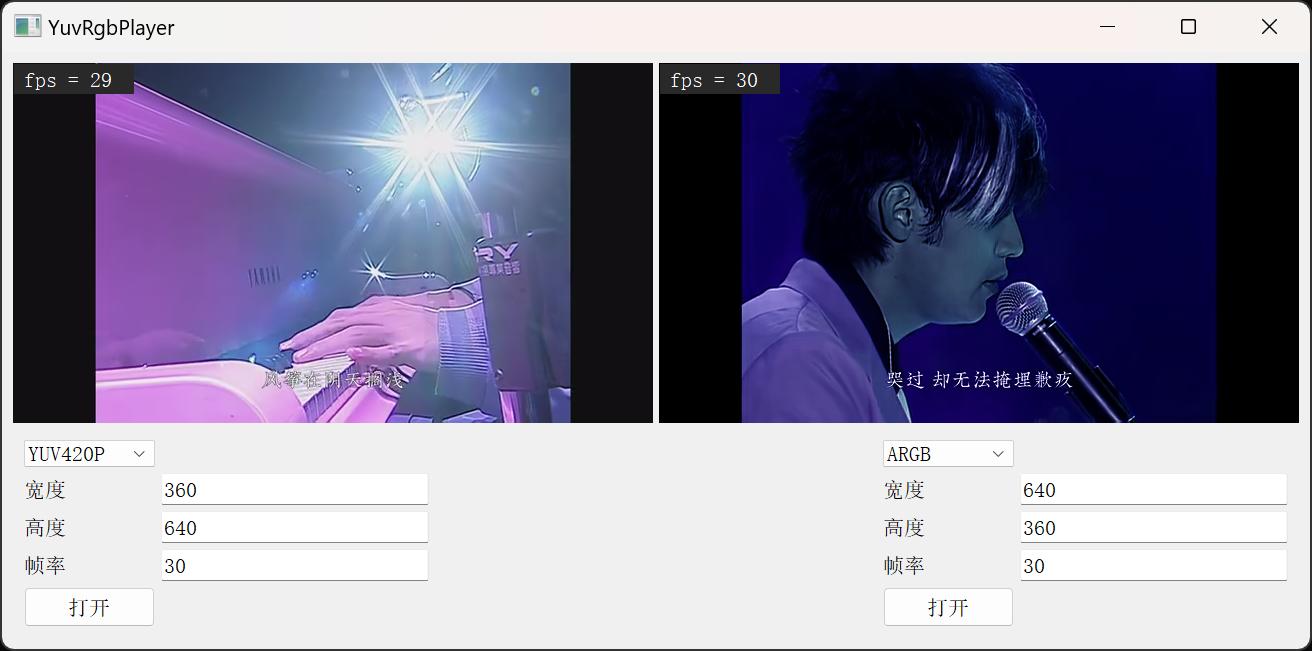
}QT播放器
具体查看012test_yuv_rgb_player
#daily/25/10/15 #daily/25/10/16
#homework
需求
- 支持多路
- 支持YUV、RGB、ARGB、BGRA、RGBA
- 两路分别播放,帧率、分辨率、格式不同
效果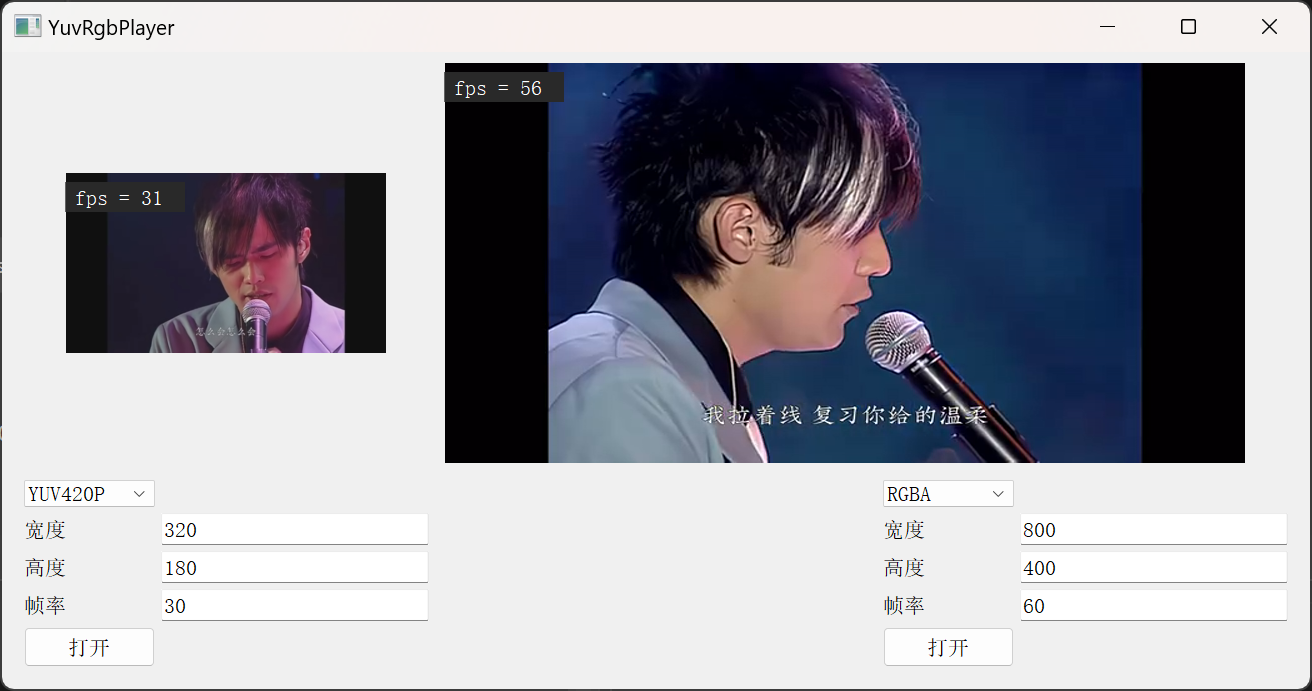
问题记录
多次打开会暂停播放
需要先关闭上一次的资源
// 如果对象已经存在则先删除
if (view_[i]) {
view_[i]->Close();
delete view_[i];
view_[i] = nullptr;
}
// 创建对象
view_[i] = XVideoView::Create(
width_[i], height_[i],
(void*)list_videos_[i]->winId(),
(XVideoView::PixFormat)fmt_[i],
XVideoView::SDL
);色差问题
是由于SDL渲染的格式产生的问题, ARGB32 和 ARGB8888 不等价
// 添加图片到纹理
SDL_PixelFormat sdl_format;
switch (fmt)
{
case XVideoView::YUV420P:
sdl_format = SDL_PIXELFORMAT_IYUV;
break;
case XVideoView::RGB:
sdl_format = SDL_PIXELFORMAT_RGB24;
break;
case XVideoView::ARGB:
sdl_format = SDL_PIXELFORMAT_ARGB32; // 这里不能选ARGB8888,会出现色差问题
break;
case XVideoView::RGBA:
sdl_format = SDL_PIXELFORMAT_RGBA32; // 这里不能选RGBA8888,会出现色差问题
break;
case XVideoView::BGRA:
sdl_format = SDL_PIXELFORMAT_BGRA32; // 这里不能选BGRA8888,会出现色差问题
break;
default:
break;
}
texture_ = SDL_CreateTexture(render_,
sdl_format,
SDL_TEXTUREACCESS_STREAMING,
w,h
);分别显示fps
因为需要每一路都显示fps,所以线程中统一1秒1刷
// 渲染线程
th_render_ = std::thread([&]() {
while (!is_exited_)
{
emit UpdateFps();
emit UpdateFrame();
MSleep(1);
}
});在UpdateFrame中实现刷新的间隔时间 1000 / fps_[i]
void YuvRgbPlayer::OnUpdateFrame()
{
static int last_pts[VIDEO_CNT] = {0,};
static int start[VIDEO_CNT] = {0,};
for (int i = 0; i < VIDEO_CNT; i++)
{
if (!view_[i] || fps_[i] < 0) continue;
// 更新视频帧
int ms = 1000 / fps_[i]; // 刷新1张图片需要的时间
// 判断是否到渲染时间
if ((clock() - last_pts[i]) / (CLOCKS_PER_SEC / 1000) >= ms)
{
last_pts[i] = clock();
view_[i]->Read();
view_[i]->Draw();
}
}
}每一个 view拥有独立的fps
#pragma once
#include <fstream>
class AVFrame;
class XVideoView
{
public:
enum PixFormat // 顺序与FFmepeg相同
{
YUV420P = 0,
RGB = 2,
ARGB = 25,
RGBA = 26,
BGRA = 28,
};
enum ViewType
{
SDL = 0
};
// 创建
static XVideoView* Create(int w, int h, void* win_id, int fmt, ViewType type = SDL);
// 打开文件
bool Open(const char* file_path);
// 读取帧
void Read();
// 绘制
bool Draw();
// 关闭
virtual bool Close() = 0;
// 缩放
void Scale(int w, int h);
// 获取fsp
int render_fps() const;
protected:
virtual bool DrawFrame() = 0;
protected:
int scale_w_;
int scale_h_;
std::ifstream ifs_;
AVFrame* frame_ = nullptr;
private:
int file_size_;
int render_fps_; // 每一个视频窗口都能拥有独立的fps
int start_;
int cnt_;
};bool XVideoView::Draw()
{
// 计算fps
cnt_++;
if (start_ <= 0)
{
start_ = clock();
}
else {
if ((clock() - start_) / (CLOCKS_PER_SEC / 1000) >= 1000)
{
render_fps_ = cnt_;
start_ = 0;
cnt_ = 0;
}
}
// 绘制这一帧图像
DrawFrame();
return true;
}线程安全
#todo
抗锯齿
#todo
解耦合
当前库中的xsdl中使用的是avframe,造成了接口的不灵活,两个类强绑定了
- 不便于测试:xsdl中只能处理avframe中的数据,其他的数据也只能先封装成avframe
- 不便于维护:当avframe结构体发生变化后,xsdl可能也需要同步地进行修改
视频编码
编码原理
像素格式过大,需要编码压缩
帧内压缩:图片压缩
帧间压缩:只存与上一张的变化的内容
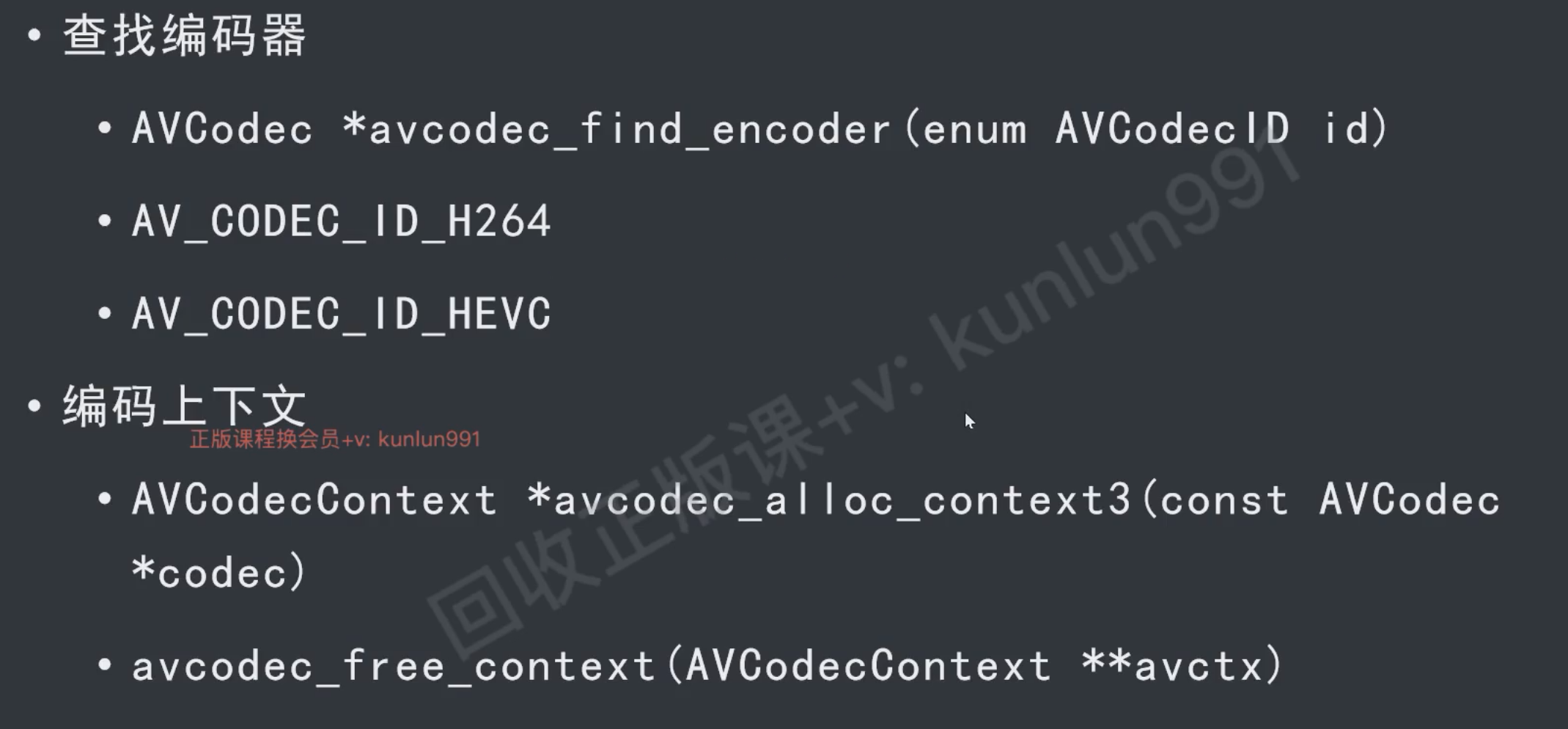
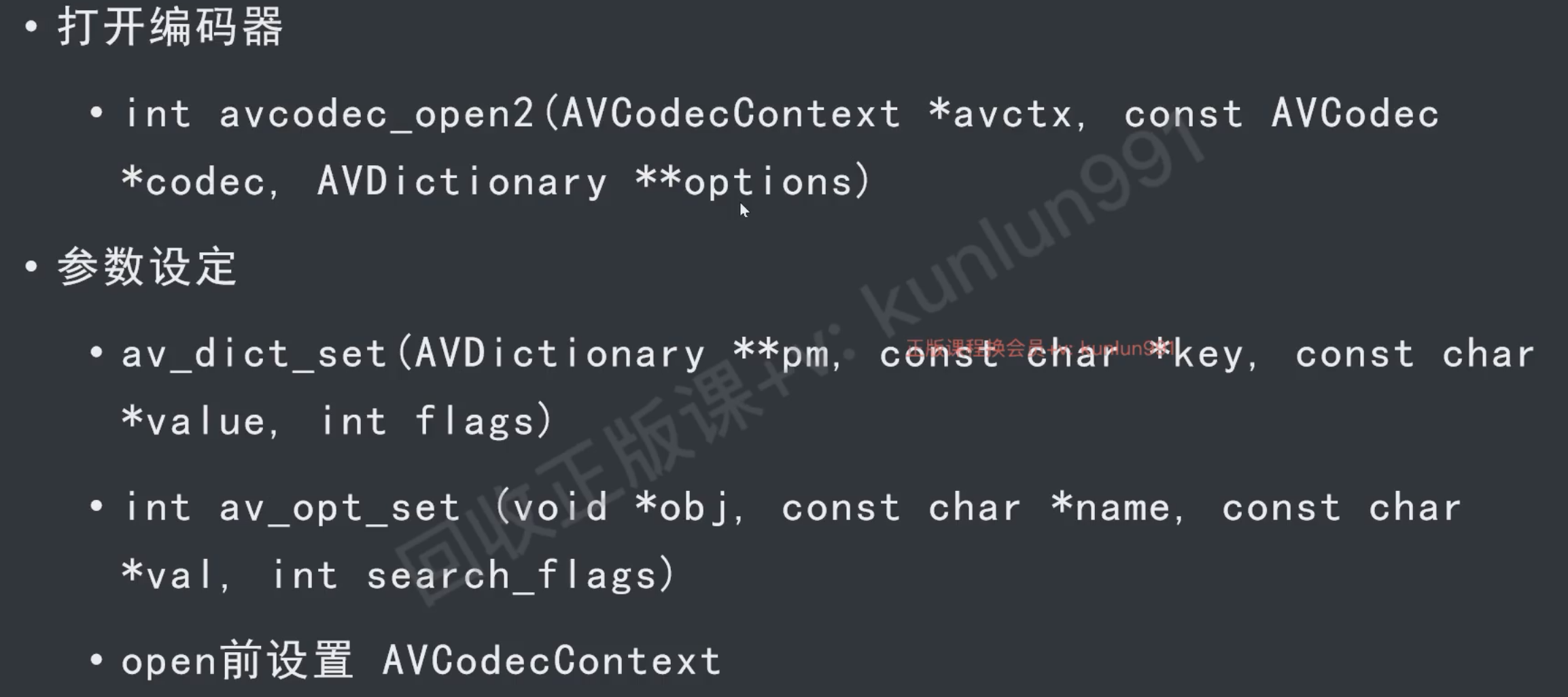
接口
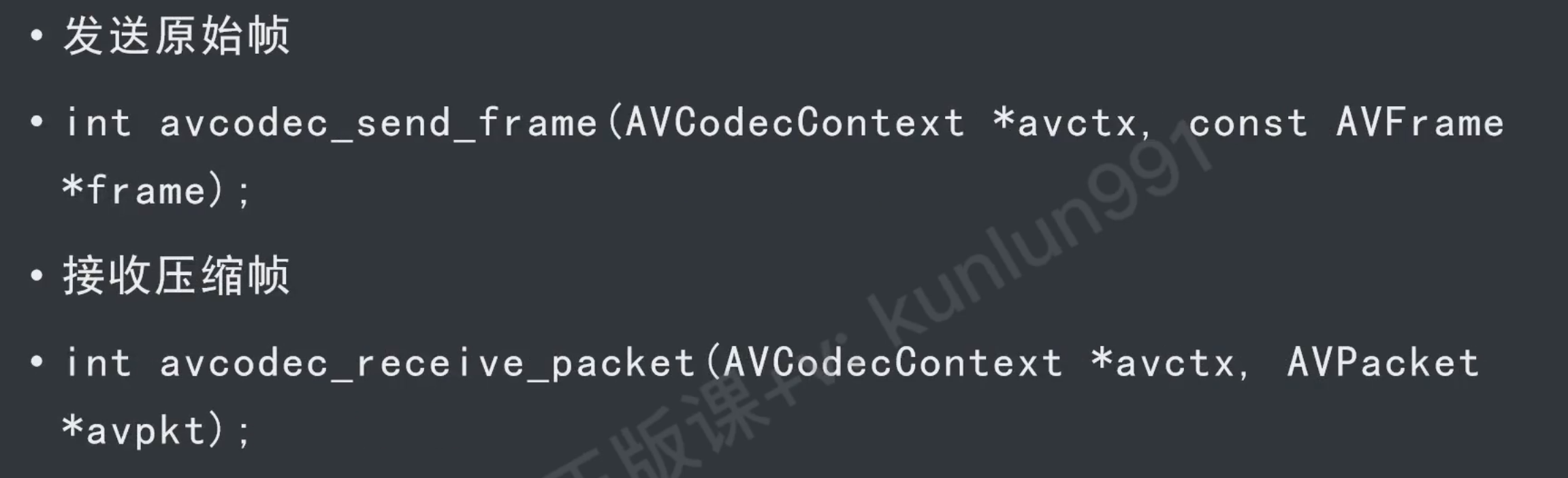
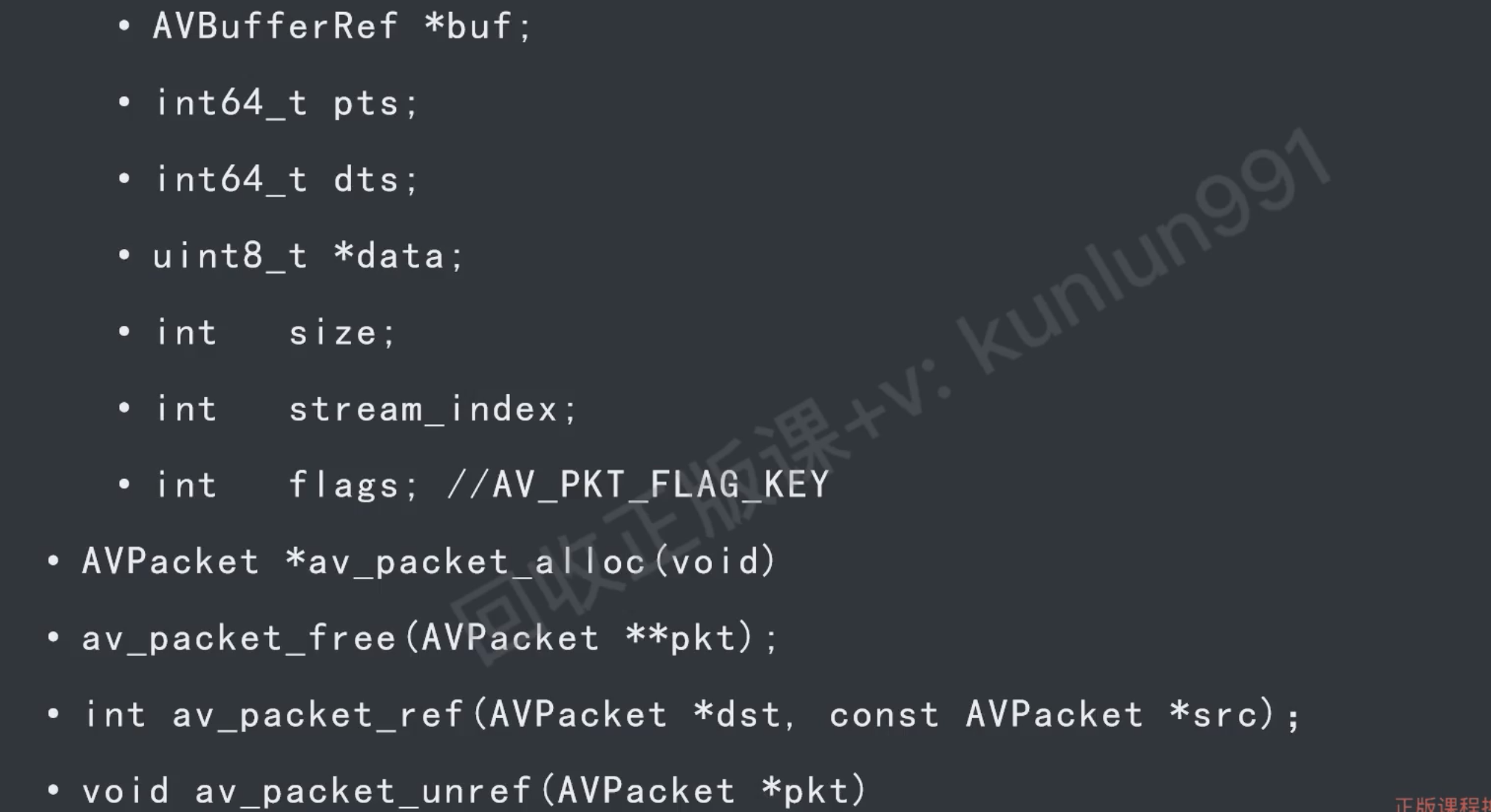
AVPacket
编码后的AVFrame
- pts 显示时间
- dts 解码时间
YUV编码成h264
ffmpeg命令行
ffmpeg -f rawvideo -video_size 640x360 -pixel_format yuv420p -framerate 30 -i ./640_360_30.yuv ./640_360_30.h264具体查看013test_yuv_encode_h264
h264只支持yuv420p格式
#include <iostream>
#include <fstream>
extern "C" {
#include "libavcodec/avcodec.h"
#include "libavutil/avutil.h"
}
#pragma comment(lib,"avcodec")
#pragma comment(lib,"avutil")
using namespace std;
#define YUV_PATH "C:\\Users\\Shelton\\Workspaces\\code\\vs\\study_ffmpeg\\assets\\640_360_30.yuv"
#define OUT_PATH "C:\\Users\\Shelton\\Workspaces\\code\\vs\\study_ffmpeg\\assets\\640_360_30.h264"
int main()
{
ifstream ifs;
ifs.open(YUV_PATH, ios::binary);
ofstream ofs;
ofs.open(OUT_PATH, ios::binary);
// 查找编码器
AVCodecID enc_id = AV_CODEC_ID_H264;
const AVCodec* enc = avcodec_find_encoder(enc_id);
// 编辑上下文
AVCodecContext* context = avcodec_alloc_context3(enc);
context->width = 640;
context->height = 360;
context->pix_fmt = AV_PIX_FMT_YUV420P;
context->time_base = { 1,25 };
context->thread_count = 16;
// 打开编码器
avcodec_open2(context, enc, NULL);
// 发送原始帧
AVFrame* frame = av_frame_alloc();
frame->width = 640;
frame->height = 360;
frame->format = AV_PIX_FMT_YUV420P;
av_frame_get_buffer(frame, 0);
AVPacket* pkt = av_packet_alloc();
int i = 0;
for (;;)
{
ifs.read((char*)frame->data[0], frame->width * frame->height);
if (ifs.gcount() == 0) break; // y的数据不对可以退出了
ifs.read((char*)frame->data[1], frame->width * frame->height / 4);
ifs.read((char*)frame->data[2], frame->width * frame->height / 4);
frame->pts = i++;
int re = avcodec_send_frame(context, frame);
if (re != 0) { // 返回值为0是success
char buf[32];
av_strerror(re, buf, 32);
cout << "err: " << buf << endl;
break;
}
// 接收编码帧,消费者模式可能存在接收多个数据帧的情况,因此需要循环
while (1)
{
re = avcodec_receive_packet(context, pkt);
if (re == 0) {
ofs.write((char*)pkt->data, pkt->size);
av_packet_unref(pkt); // 出这次循环的时候引用计数不会自动-1,需要手动减
}
else if (re == AVERROR(EAGAIN) || re == AVERROR(EINVAL))
{
break;
}
else
{
char buf[32];
av_strerror(re, buf, 32);
break;
}
}
}
// 释放
avcodec_free_context(&context);
av_frame_free(&frame);
av_packet_free(&pkt);
ifs.close();
ofs.close();
}手动生成yuv数据
具体查看 013test_yuv_encode_h264
效果
本质和读文件是一样的,手动去填写avframe中的yuv的数据
- avframe中存储yuv是平面存储的所以uv平面的宽高都是y平面的1/2
- 文件的连续存储中uv才会和y宽度一样
// y
for (int h = 0; h < frame->height; h++)
{
for (int w = 0; w < frame->width; w++)
{
// 让每一帧的画面不同所以赋的值是变量
frame->data[0][h * frame->linesize[0] + w] = 200+i * 2;
}
}
// uv
for (int h = 0; h < frame->height / 2; h++)
{
for (int w = 0; w < frame->width / 2; w++)
{
frame->data[1][h * frame->linesize[1] + w] = 100+i * 4;
frame->data[2][h * frame->linesize[2] + w] = 100+i * 3;
}
}h264
原理
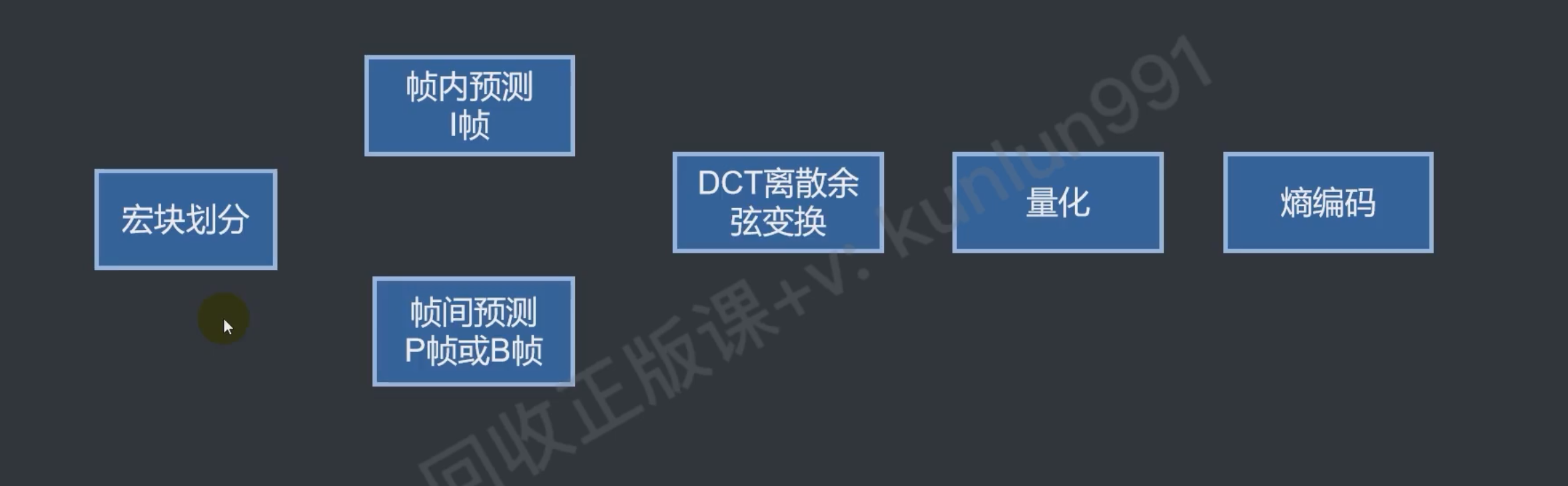
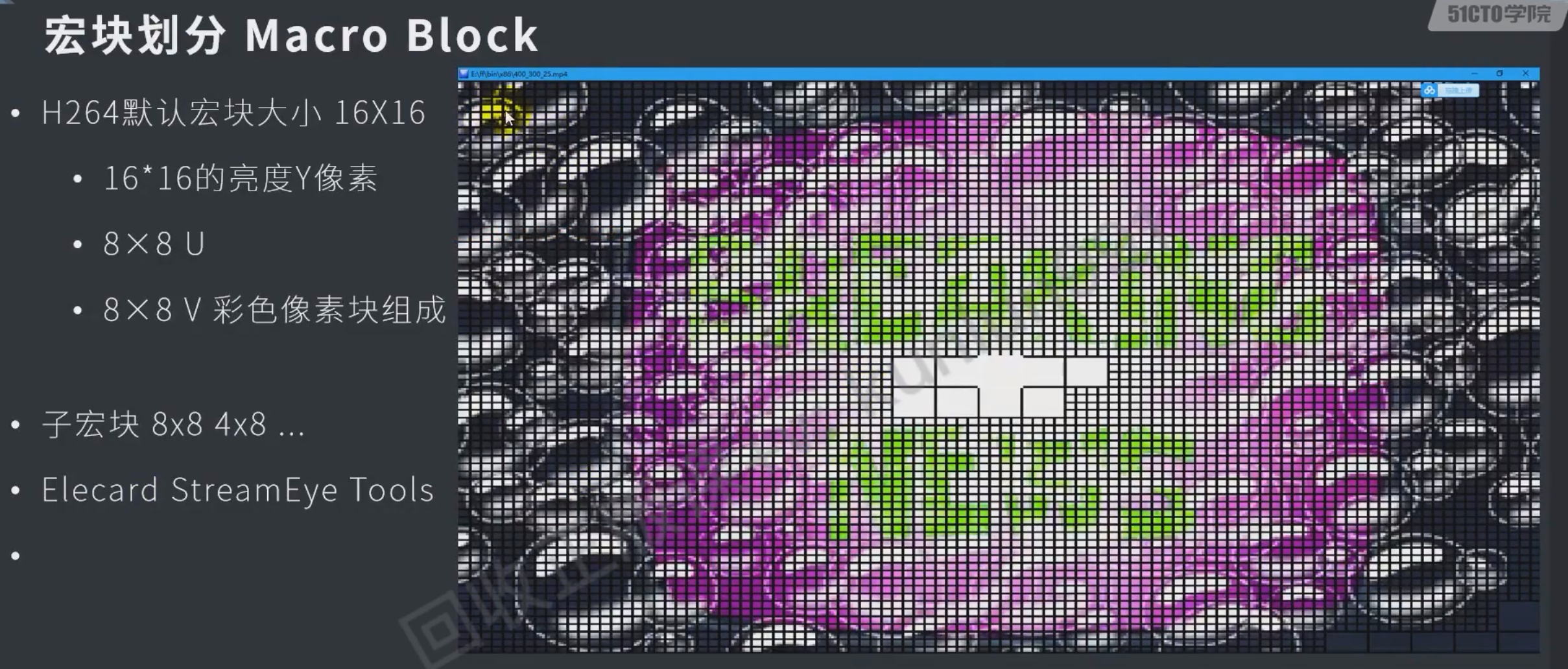
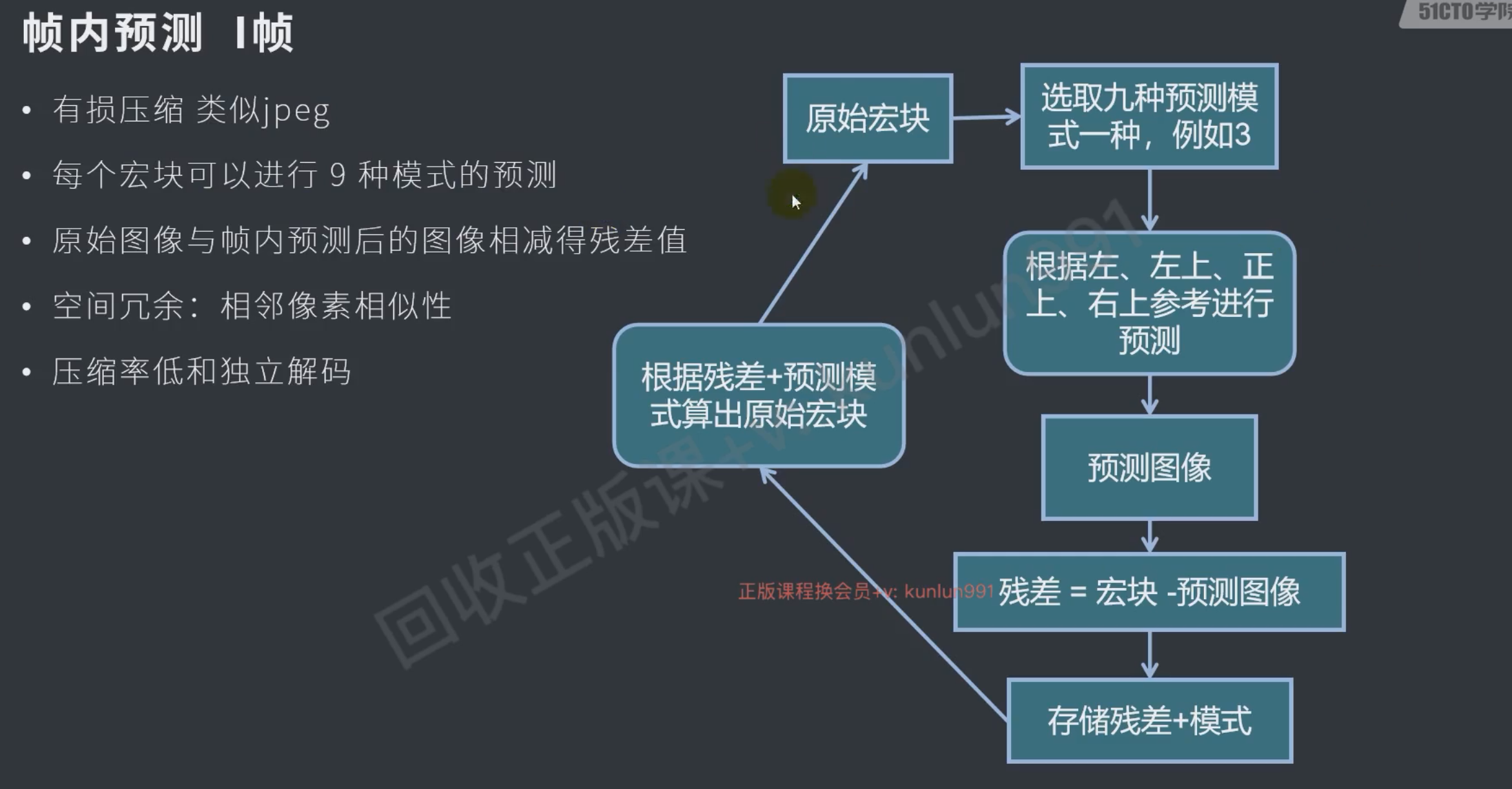
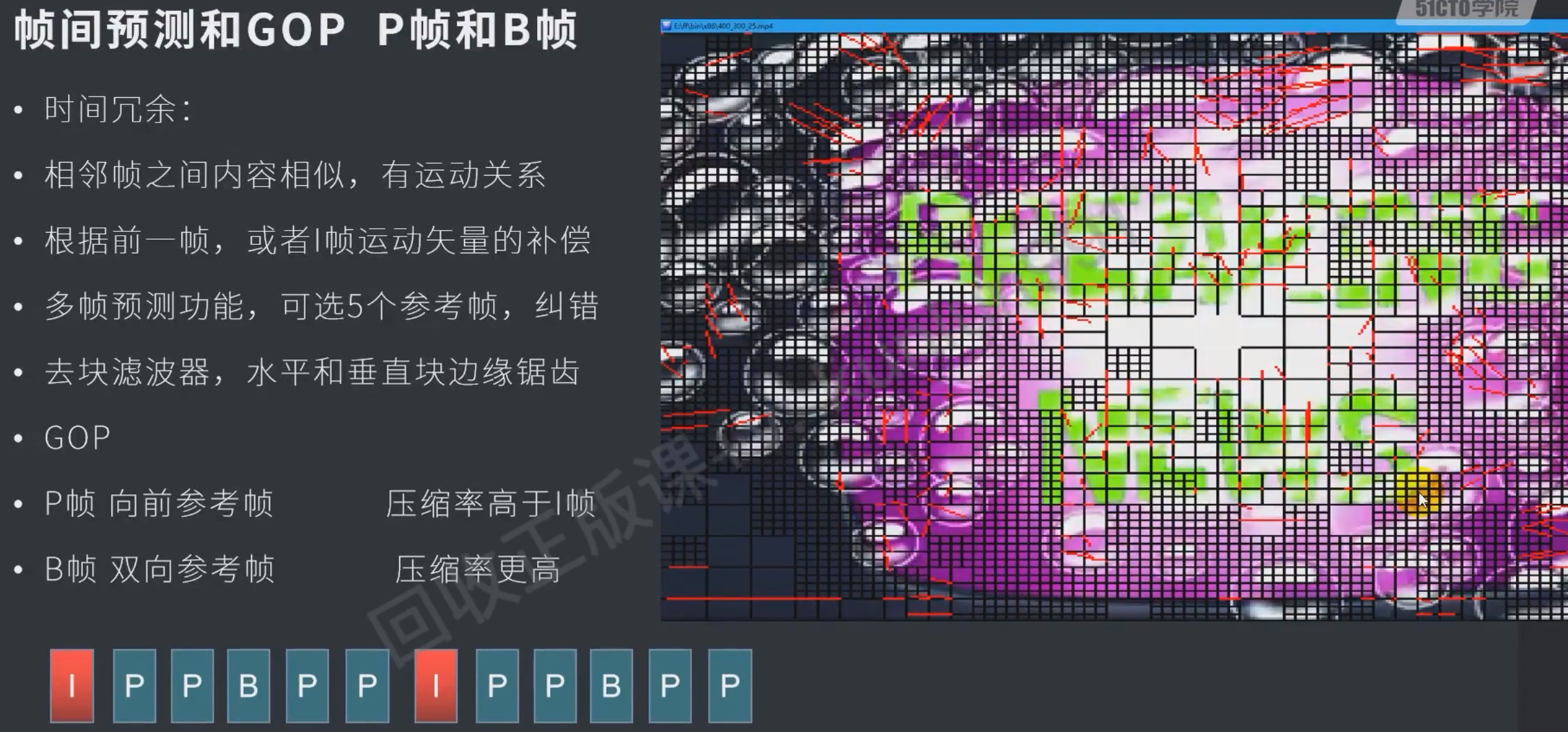
b帧会增大延迟,因为双向的要先解后一帧才能解b帧
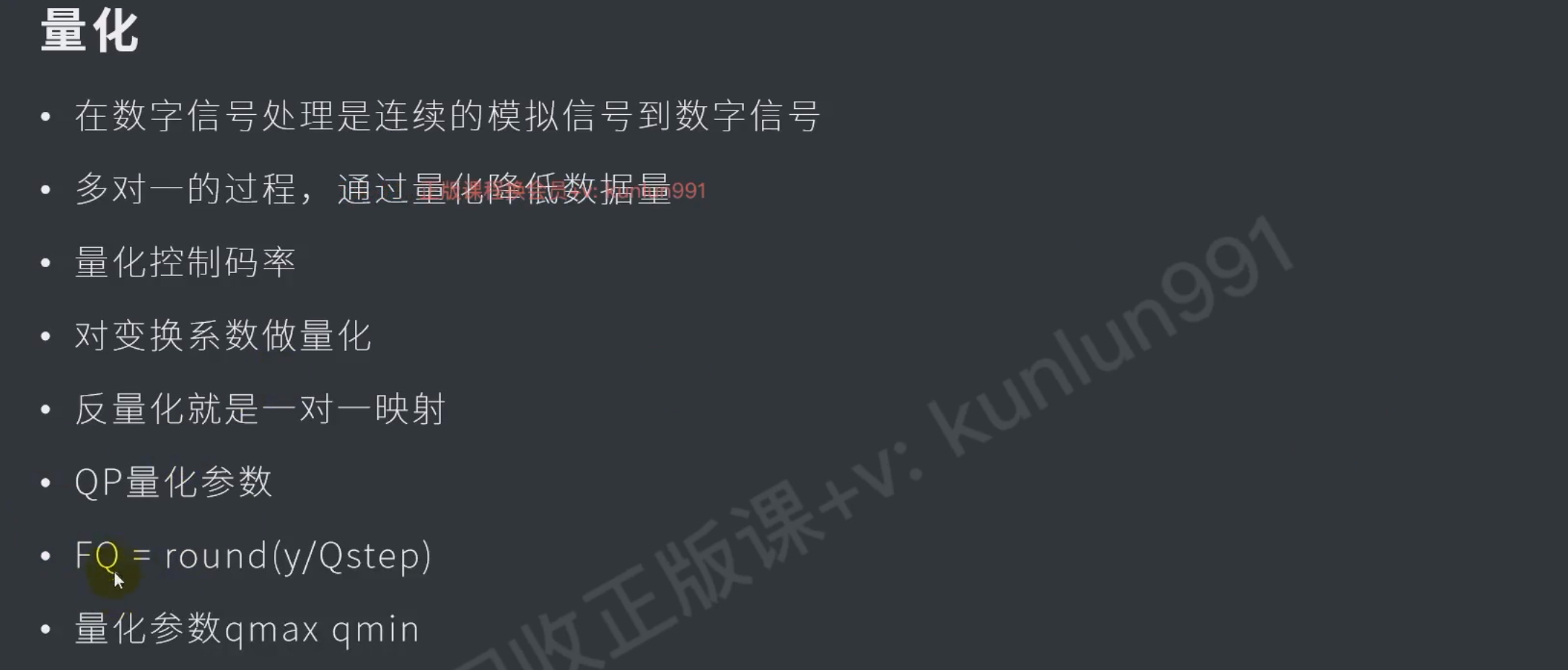
编码的时候 除以qp,解码的时候 乘以qp ,这里是有损的压缩
- qp越大损失越大

无损
- 哈夫曼编码
- 算术编码 #question
好的,我们用一个非常直观的方式来理解算术编码。
你可以把它想象成 **“用一个分数来表示整个消息”**。
---
### 核心思想
算术编码的核心思想是:**将整个要编码的消息(比如一个字符串)映射到一个0到1之间的唯一的小数区间。这个区间足够精确,以至于任何其他消息都不会映射到同一个区间。**
最终,我们存储或传输的就是这个区间中的一个代表性的小数。
---
### 一个简单的例子
假设我们有一个超级简单的字母表,只有两个字符:**A** 和 **B**。
并且我们知道它们的出现概率:
- **P(A) = 0.6**
- **P(B) = 0.4**
现在,我们要编码消息:**“BABA”**
#### 步骤1:初始化区间
我们从一个完整的区间 `[0, 1)` 开始。(注意,是左闭右开)
#### 步骤2:为每个字符划分区间
根据概率,我们把当前区间分成两段:
- **A** 占据左边部分的 60%
- **B** 占据右边部分的 40%
所以初始划分是:
- **A** 的范围是 `[0, 0.6)`
- **B** 的范围是 `[0.6, 1)`
#### 步骤3:处理第一个字符 ‘B’
我们的消息第一个字符是 **B**。所以,我们**选择 B 对应的区间 `[0.6, 1)`**,并把它作为新的当前区间。
#### 步骤4:在新区间内再次划分
现在,我们在新的当前区间 `[0.6, 1)` 上,再次按照同样的概率(A占60%,B占40%)进行划分。
这个区间的长度是 `1 - 0.6 = 0.4`。
- **A** 的新范围:从 0.6 开始,占据 0.4 的 60% => `0.4 * 0.6 = 0.24`。所以范围是 `[0.6, 0.6 + 0.24)` = `[0.6, 0.84)`
- **B** 的新范围:从 0.84 开始,占据 0.4 的 40% => `0.4 * 0.4 = 0.16`。所以范围是 `[0.84, 0.84 + 0.16)` = `[0.84, 1.0)`
#### 步骤5:处理第二个字符 ‘A’
第二个字符是 **A**。所以我们选择 A 的区间 `[0.6, 0.84)` 作为新的当前区间。
#### 步骤6:继续迭代
我们不断重复这个过程:
1. **当前区间 `[0.6, 0.84)`,长度 = 0.24**
- **A**:`[0.6, 0.6 + 0.24*0.6)` = `[0.6, 0.744)`
- **B**:`[0.744, 0.744 + 0.24*0.4)` = `[0.744, 0.84)`
- 下一个字符是 **B** -> 新区间 = `[0.744, 0.84)`
2. **当前区间 `[0.744, 0.84)`,长度 = 0.096**
- **A**:`[0.744, 0.744 + 0.096*0.6)` = `[0.744, 0.8016)`
- **B**:`[0.8016, 0.8016 + 0.096*0.4)` = `[0.8016, 0.84)`
- 最后一个字符是 **A** -> 最终区间 = `[0.744, 0.8016)`
#### 最终结果
消息 **“BABA”** 被唯一地映射到了区间 `[0.744, 0.8016)`。
---
### 如何输出编码?
我们不需要传输整个区间,只需要传输这个区间里的**任意一个数**即可。比如,我们可以选择区间的下限 `0.744`,或者中点 `(0.744 + 0.8016)/2 = 0.7728`。
假设我们选择 **0.7728**。在二进制中,这个数可能是 `0.11000110...`(只是举例)。我们只需要将足够的二进制位传输出去,让接收方能够唯一确定这个区间即可。
**解码过程** 是编码的逆过程:解码器同样从 `[0, 1)` 开始,根据收到的数字(如0.7728)落在哪个字符的区间,就解码出哪个字符,然后和编码器一样更新区间,循环往复,直到解码出所有字符。
---
### 为什么说它高效?
1. **匹配熵**:算术编码的效率非常接近香农熵的理论极限。出现概率高的字符(如A,概率0.6)只会稍微缩小区间,而概率低的字符(如B,概率0.4)会显著缩小区间。最终区间的大小就等于所有字符概率的乘积:`0.4 * 0.6 * 0.4 * 0.6 = 0.0576`。`-log2(0.0576) ≈ 4.12` 位,而我们用一个浮点数就表示了,非常高效。
2. **处理小数概率轻而易举**:不像哈夫曼编码必须为每个字符分配整数位的码字,算术编码可以轻松处理像 `P(A)=0.567` 这样奇怪的概率。
3. **自适应模型**:我们甚至可以在编码过程中动态调整概率模型,编码器和解码器同步更新概率,从而更好地适应数据本身的变化(比如文本中不同部分字符分布不同)。
---
### 总结
你可以把算术编码理解为一个 **“概率区间收缩器”**:
- **输入**:一串消息 + 一个概率模型。
- **过程**:从 `[0, 1)` 开始,每读入一个字符,就根据它的概率将当前区间收缩到对应的子区间。
- **输出**:最终区间里的一个数字。
这个数字就是整个消息的编码。它之所以强大,是因为它**不再为单个字符编码,而是为整个消息序列生成一个编码**,从而突破了“整数位”的限制,实现了近乎无损的压缩效率。这个A出现概率是0.6,B出现的概率是0.4是遍历全文统计出来的?传输的时候没有传送整个区间,那么解码时候的区间是怎么得到的,如果和编码的区间产生误差,不就是有损了吗问得非常好!这两个问题直击算术编码的核心机制。我们来逐一拆解。
---
### 问题一:概率模型是哪里来的?
你提到的 `P(A)=0.6, P(B)=0.4` 这个概率模型,确实是需要编码器和解码器**在开始处理数据前就达成共识**的。这个共识的来源主要有两种方式:
#### 1. 静态模型
- **方式**:在编码开始前,先扫描整个被编码的消息(比如一个文件),统计出每个字符出现的频率。然后,编码器将这个**频率表(概率模型)** 放在压缩数据的最前面,一起传输给解码器。
- **流程**:
1. 编码器:扫描全文 -> 生成频率表 -> 将频率表写入压缩文件头 -> 开始算术编码 -> 将代表最终区间的数字写入文件。
2. 解码器:读取文件头 -> 得到频率表 -> 读取代表区间的数字 -> 开始算术解码。
- **优点**:简单直观。
- **缺点**:需要额外传输频率表,对于小文件来说,这部分开销占比可能很大。
#### 2. 自适应模型
这是更常用、更优雅的方式。
- **方式**:编码器和解码器从同一个初始状态开始(例如,开始时他们都认为A和B出现的概率相等,各为0.5)。每处理一个字符,双方就**同步更新**这个概率模型。
- **流程**:
1. **初始状态**:编码器和解码器都约定好,初始计数为:A出现1次,B出现1次(这是一种平滑处理,避免概率为0)。所以初始概率 P(A) = 1/2, P(B) = 1/2。
2. **编码第一个字符**:假设是 ‘B’。编码器使用当前的模型(P(A)=0.5, P(B)=0.5)对 ‘B’ 进行区间划分和收缩。
3. **更新模型**:编码器处理完 ‘B’ 后,更新内部计数:B的计数加1。现在计数变为 A:1, B:2。所以新的概率是 P(A)=1/3, P(B)=2/3。
4. **解码第一个字符**:解码器拿到最终的编码数字(比如0.7728),它也用初始模型(P(A)=0.5, P(B)=0.5)进行判断,发现0.7728落在B的区间,于是它解码出 ‘B’。
5. **关键一步**:解码器解码出 ‘B’ 后,**也以完全相同的规则更新自己的模型**:将B的计数加1。现在解码器的模型也变成了 A:1, B:2,即 P(A)=1/3, P(B)=2/3。
6. **循环**:处理下一个字符时,双方都已经在使用更新后的、完全一致的模型了。
通过这种方式,**编码器和解码器的概率模型在任何时刻都是严格同步的**,完全不需要传输频率表(除了初始状态约定)。
---
### 问题二:如何保证解码无误差?区间如何同步?
这是算术编码实现无损的关键。解码器**不需要事先知道编码器的最终区间**,它通过一个“重放”的过程来重现一切。
我们回到之前的例子,但这次我们用**自适应模型**来看解码端是如何工作的。
**约定**:初始计数 A=1, B=1。概率 P(A)=1/2, P(B)=1/2。
#### 编码过程(简化记录):
1. 当前区间 `[0, 1)`,模型 P(A)=0.5, P(B)=0.5。
- 字符 ‘B’ -> 选择区间 `[0.5, 1)` -> 新区间 `[0.5, 1)`
- **更新模型**:B计数+1 -> A:1, B:2 -> P(A)=1/3, P(B)=2/3
2. 当前区间 `[0.5, 1)`,模型 P(A)=1/3, P(B)=2/3。
- 字符 ‘A’ -> 选择区间 `[0.5, 0.666...)` -> 新区间 `[0.5, 0.666...)`
- **更新模型**:A计数+1 -> A:2, B:2 -> P(A)=1/2, P(B)=1/2
3. 当前区间 `[0.5, 0.666...)`,模型 P(A)=1/2, P(B)=1/2。
- 字符 ‘B’ -> 选择区间 `[0.583..., 0.666...)`
- **更新模型**:B计数+1 -> A:2, B:3 -> P(A)=2/5, P(B)=3/5
4. 当前区间 `[0.583..., 0.666...)`,模型 P(A)=2/5, P(B)=3/5。
- 字符 ‘A’ -> **最终区间** `[0.583..., 0.6...)`
- **更新模型**:(编码完成,最后这个更新解码器用不到)
编码器最终传输一个数字,比如这个最终区间的中点 `0.5912`。
#### 解码过程(神奇的重放):
解码器拿到数字 `0.5912`。
1. **初始状态**:当前区间 `[0, 1)`,模型 P(A)=0.5, P(B)=0.5。
- 判断 `0.5912` 落在哪个区间?它落在 `[0.5, 1)`,这是B的区间。
- **解码出 ‘B’**。
- **关键:更新模型** -> B计数+1 -> A:1, B:2 -> P(A)=1/3, P(B)=2/3。
- **关键:模仿编码器收缩区间** -> 将当前区间收缩为B的区间 `[0.5, 1)`。
2. **新状态**:当前区间 `[0.5, 1)`,数字 `0.5912`,模型 P(A)=1/3, P(B)=2/3。
- 在当前区间内,A的范围是 `[0.5, 0.666...)`,B的范围是 `[0.666..., 1)`。
- `0.5912` 落在 `[0.5, 0.666...)`,这是A的区间。
- **解码出 ‘A’**。
- **更新模型** -> A计数+1 -> A:2, B:2 -> P(A)=1/2, P(B)=1/2。
- **收缩区间** -> 将当前区间收缩为A的区间 `[0.5, 0.666...)`。
3. **新状态**:当前区间 `[0.5, 0.666...)`,数字 `0.5912`,模型 P(A)=1/2, P(B)=1/2。
- 在当前区间内,A的范围是 `[0.5, 0.583...)`,B的范围是 `[0.583..., 0.666...)`。
- `0.5912` 落在 `[0.583..., 0.666...)`,这是B的区间。
- **解码出 ‘B’**。
- **更新模型** -> ...
- **收缩区间** -> ...
如此继续,解码器就能完全重现编码器的步骤,一个字符一个字符地解码出整个消息 “BABA”。
### 结论
1. **概率来源**:通过**预传输静态模型**或**动态自适应模型**,确保编解码双方模型一致。
2. **无误差原理**:解码器通过收到的**一个数字**,在**同步的概率模型**和**相同的区间收缩规则**下,**重放了编码器的整个工作流程**。它不是在“猜测”区间,而是在“计算”出和编码器一模一样的区间。只要传输的数字精度足够(在实现中通常使用整数和位操作来保证无限精度模拟),这个过程就是完全无损的。
这种“数字指导下的重放”机制,是算术编码既高效又无损的精髓所在。编码器参数
预设

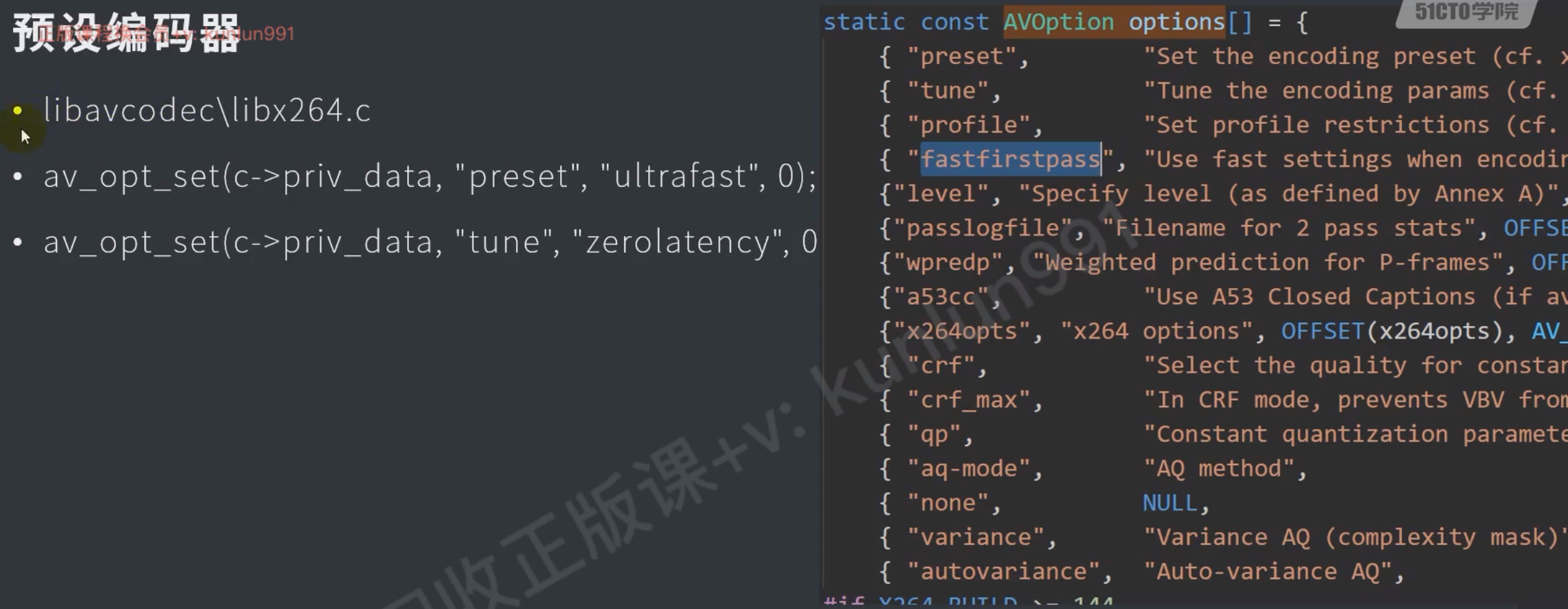
AVCodecContext* context = avcodec_alloc_context3(enc_context);
context->width = 640;
context->height = 360;
context->pix_fmt = AV_PIX_FMT_YUV420P;
context->time_base = { 1,25 };
context->thread_count = 16;
// 其他参数设置
context->max_b_frames = 0; // 无b帧,会减少延迟,但增大编码后的文件体积
av_opt_set(context->priv_data,"preset","ultrafast",0); // 预设 最快
av_opt_set(context->priv_data,"tune","zerolatency",0); // 优化 零延迟码率
具体参考014test_nalu_unpacked
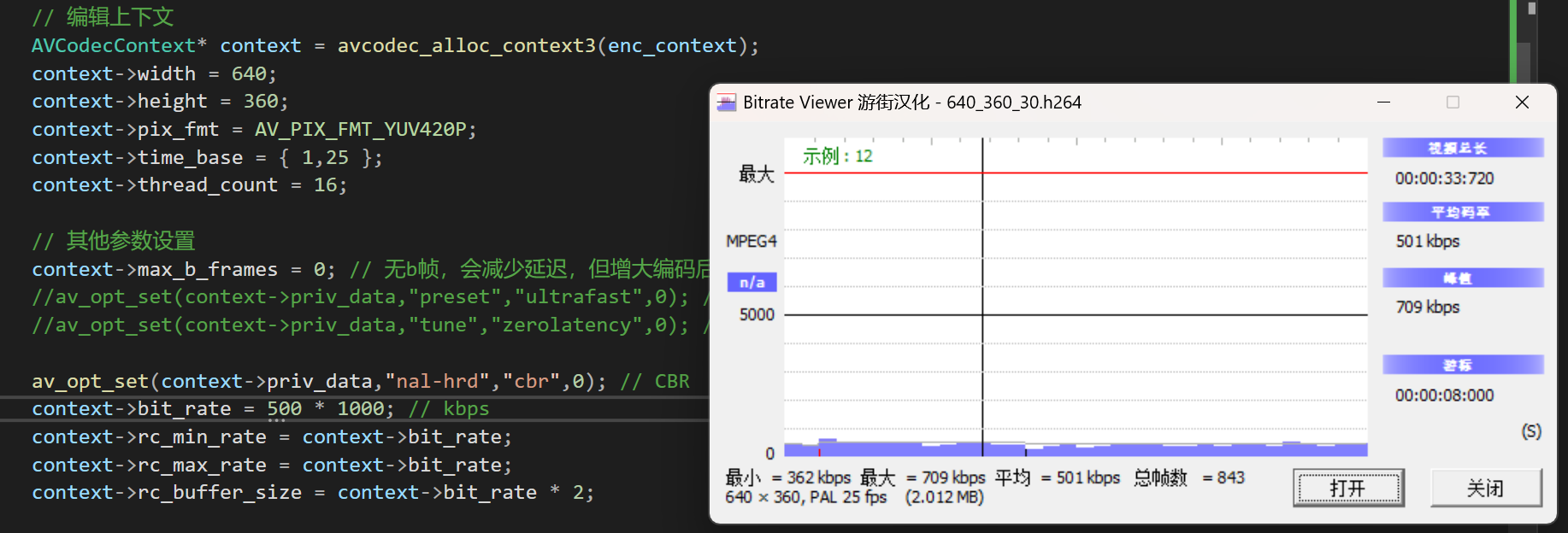
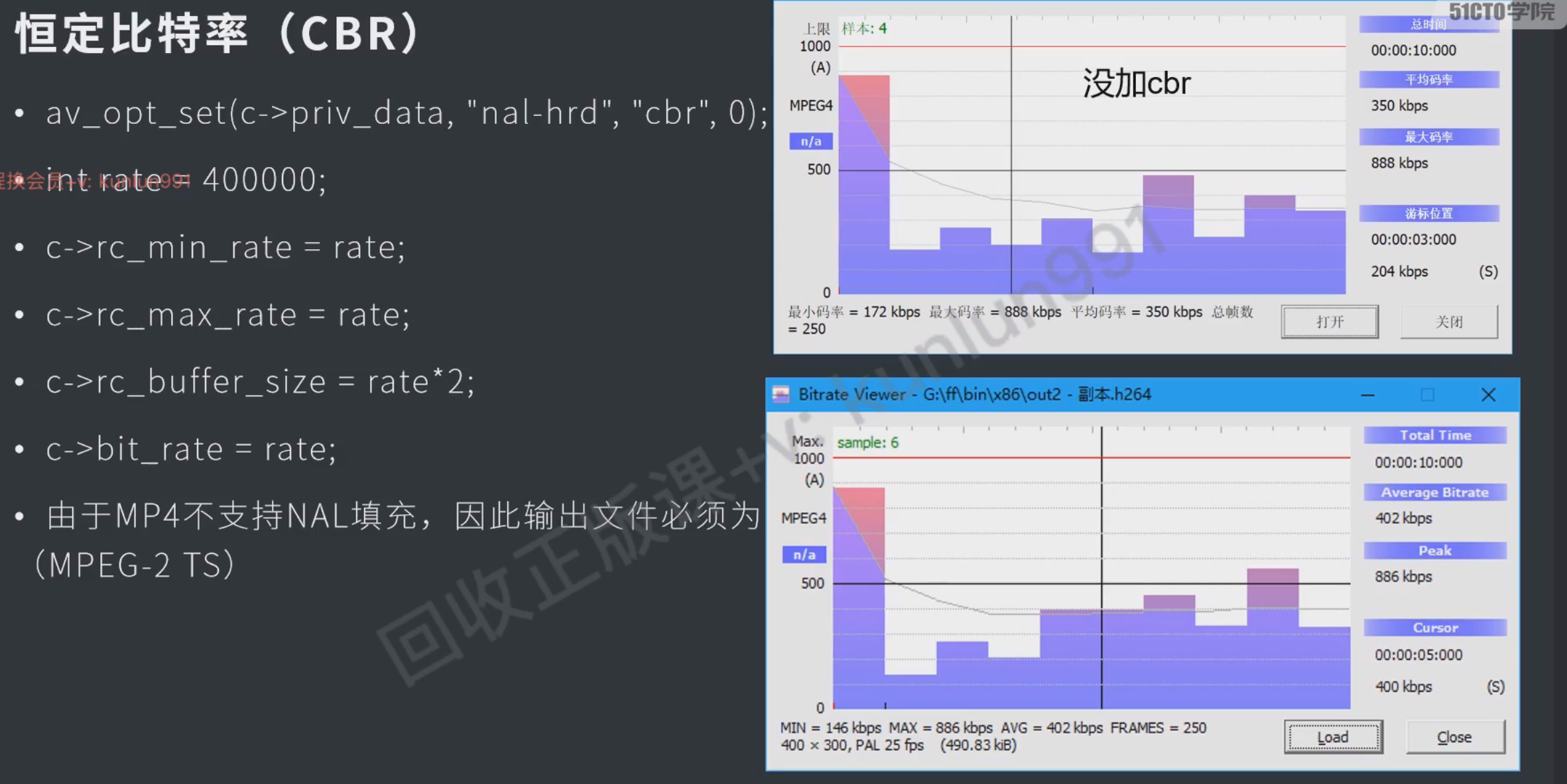
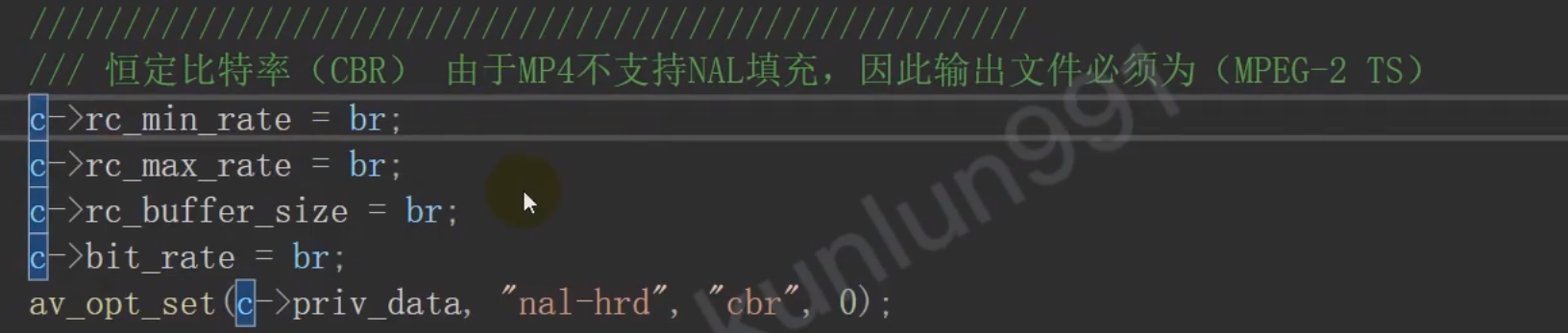
都是用来压缩体积的,用bitrate_view可以查看h264的码率
- ABR 平均比特率控制
- CQP 恒定质量
- CBR 恒定比特率
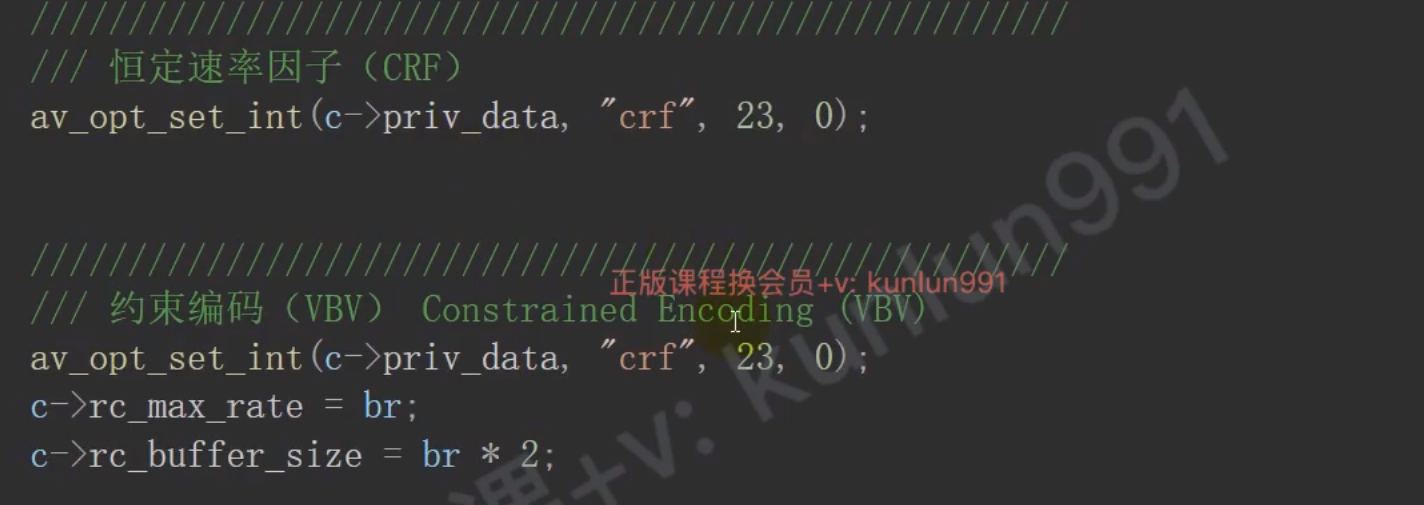
- CRF 恒定速率因子
av_opt_set(context->priv_data, "crf", "23", 0);
码率


画面变大比较大时可能会模糊

二者配合使用
IDR帧

0001 + head +




0001 1111 = 1f
减少b帧会让编码后的体积增大
- 因为b帧是前后参考的,在i、p、b中体积是最小的,但会产生延时
// 编辑上下文
AVCodecContext* context = avcodec_alloc_context3(enc_context);
// 其他参数设置
context->max_b_frames = 0; // 无b帧拆包
具体参考014test_nalu_unpacked
拆包抽出 sps pps #done
pack的起始的第一个字节是 0001
printf("%02x %02x %02x %02x"
, pkt->data[0]
, pkt->data[1]
, pkt->data[2]
, pkt->data[3]
);
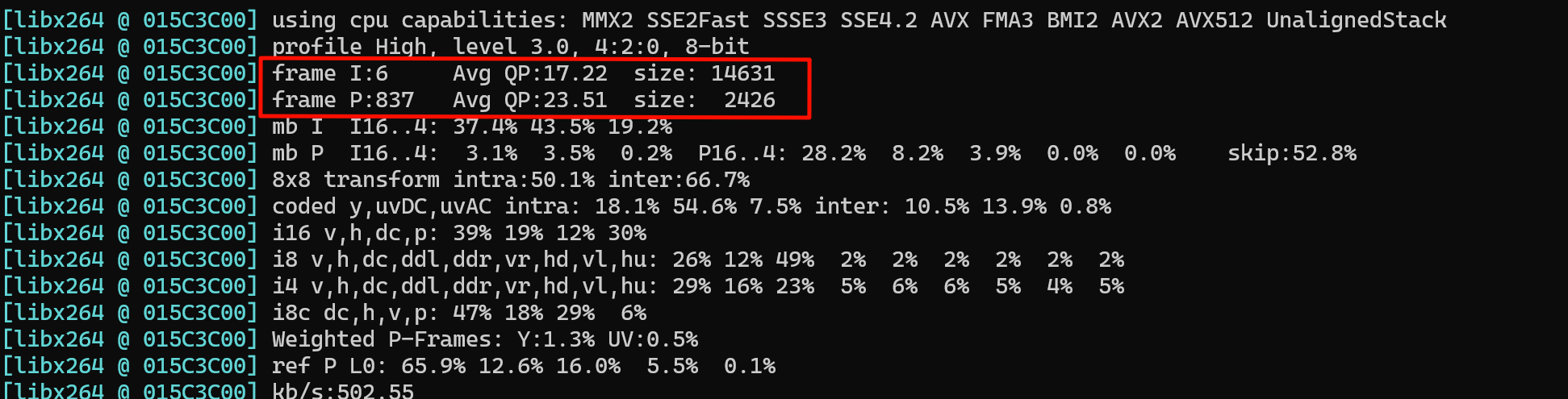
return -1;每一个IDR帧都是以0001起始的,也就是说第一帧必定是I帧
一共6个i帧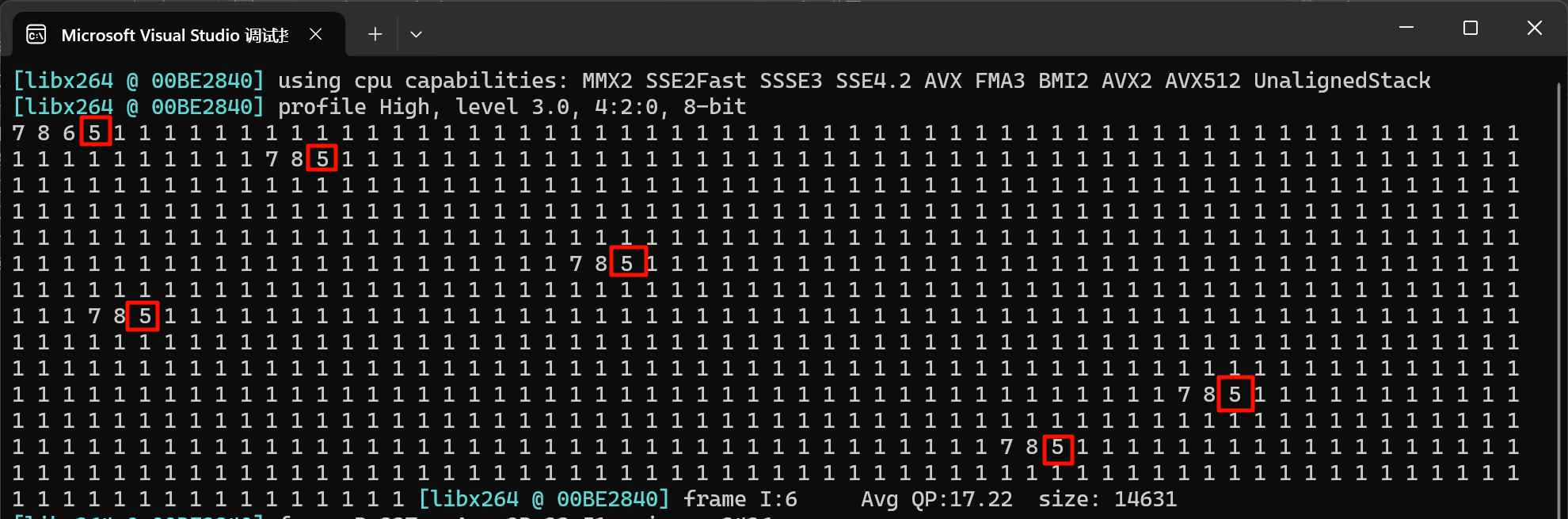
header位一个字节中包含一个 禁止1位,优先级2位,类型5位
// 先通过 001或者0001找到i帧,取后第二个字节就是head了,其中后5位就是nalu
for (int i = 0; i < pkt->size - 3; i++)
{
if (pkt->data[i] == 0 && pkt->data[i + 1] == 0 && pkt->data[i + 2] == 1) {
unsigned char header = pkt->data[i+3]; // 1个字节
//printf("%02x\n", header); // 67 = 0110 1111
/*
0 = 0 // forbiden_bit
11 = 3 // nal_reference_bit 优先级
01111 = 7(sps) // nal_unit_type 类型
*/
unsigned char nalu = header & 0x1f; // 与上 0001 1111 就是后5位了
printf("%x ", nalu); // 7 = sps , 5 = idr
}
}h265 (HEVC)
让ffmpeg支持一下avs3 #todo